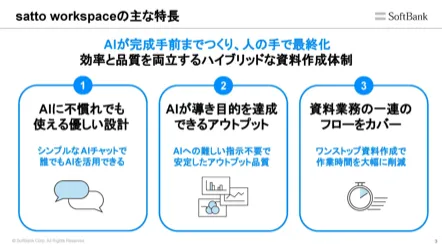
あの資料どこだっけ?資料探索にもう時間はかけない。過去の遺産を武器にする新常識。

新しい企画書に取り掛かるとき、「この市場分析、去年のプロジェクトで誰かがまとめていたはずだ」と感じることはないでしょうか。
組織のどこかに資産が眠っている。しかし、それをいざ探そうとすると、多くの人が「迷宮」に迷い込みます。フォルダの階層を一つずつ確認し、日付の羅列から目当てのファイルを探し出す。似たようなファイル名の資料を数件開いては閉じる。
こうした作業に1時間を費やした末、結局「探すより、ゼロから作った方が早い」と諦めてしまう。この瞬間、組織の資産はリセットされます。常に土台から家を建て直しているような構造的な徒労こそが、多くのBtoB企業が抱える課題です。
なぜ組織は「記憶喪失」を繰り返すのか
私たちは答えを持っているはずなのに、なぜそこに辿り着けないのでしょうか。その理由は、人間の記憶とPCの保存構造に大きな隔たりがあるからです。

ファイル名という記号による管理が「文脈」へのアクセスを阻んでいる
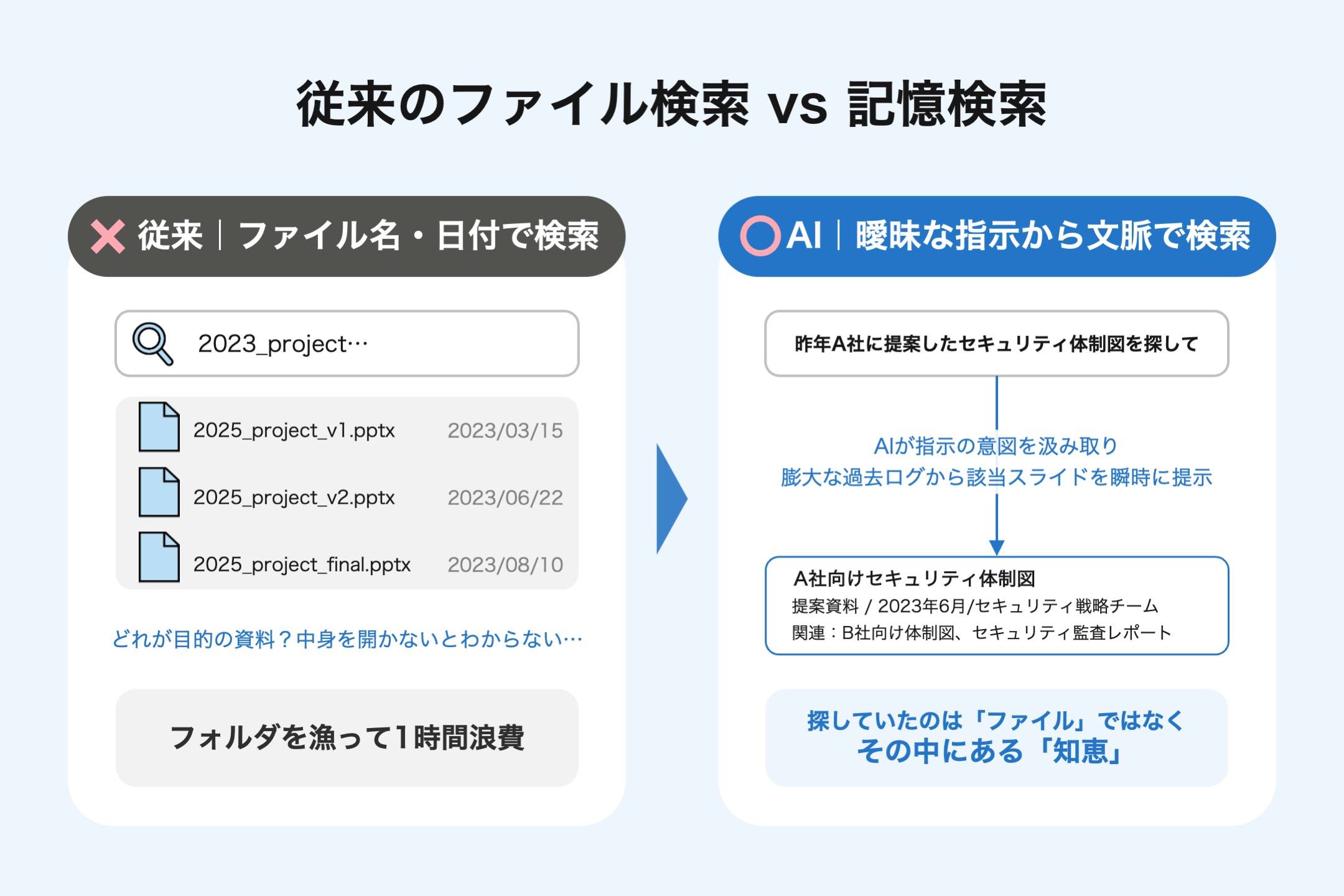
従来のファイル検索は、ファイル名や更新日という「記号」に依存しています。一方で、人が思い出したいのは「2023_project_v2.pptx」といった記号ではありません。「〇〇業界への参入障壁を分析したスライド」という文脈(コンテキスト)のはずです。
記号でしか検索できない仕組みでは、本当に必要な情報にアクセスできません。この「情報の検索性」の欠如が、資料探索の時間を増大させる根本的な原因といえます。
非構造化データが検索の精度を下げ、資産の再利用を阻んでいる
ビジネス資料の多くは、画像やグラフ、テキストが混在する「非構造化データ」です。キーワードが部分的に一致しても、そのスライドが「成功事例」なのか「課題の指摘」なのかといった文脈までは読み取れません。
結果として、他部署がすでに解決した「ベストプラクティス」も、共有サーバーの中で眠り続けることになります。
AIによる「検索」が実現する、組織知の活用
こうした課題を解決するのが、RAG(検索拡張生成)技術を活用した「記憶検索」です。
曖昧な指示から「文脈」を理解して抽出する
最新のAIワークスペースでは、ファイル名を覚えている必要はありません。隣の席の同僚に尋ねるような感覚で、「昨年、A社に提案した際のセキュリティ体制図を探して」と問いかけるだけです。
AIが指示の意図を汲み取り、膨大な過去ログの中から該当するスライドを瞬時に提示してくれるでしょう。あなたが探していたのは「ファイル」そのものではなく、その中にある「知恵」だったはずです。
過去の成果をベースに、現在の資料を再構成する
単に見つけるだけでなく、過去の資産を「今回の案件」に合わせてアレンジすることも可能です。組織が過去に導き出した到達点をベースにできるため、作成者は「今回ならではの差分」にだけ集中すればよくなります。
AI活用前に知っておきたい注意点
便利な記憶検索ですが、導入にあたっては以下の2点に留意が必要です。
- 情報のアクセス権限の整理 すべての資料を検索対象にすると、本来秘匿すべき情報まで露出するリスクがあります。部署やプロジェクトごとに適切な閲覧権限を設定することが不可欠です。
- データの「鮮度」と「質」の担保 古いデータが混在しすぎると、検索結果の精度が落ちる可能性があります。定期的に「アーカイブ用」と「アクティブ用」でデータを分ける運用ルールを検討しましょう。
実践ステップ:ナレッジ活用をどう始めるか
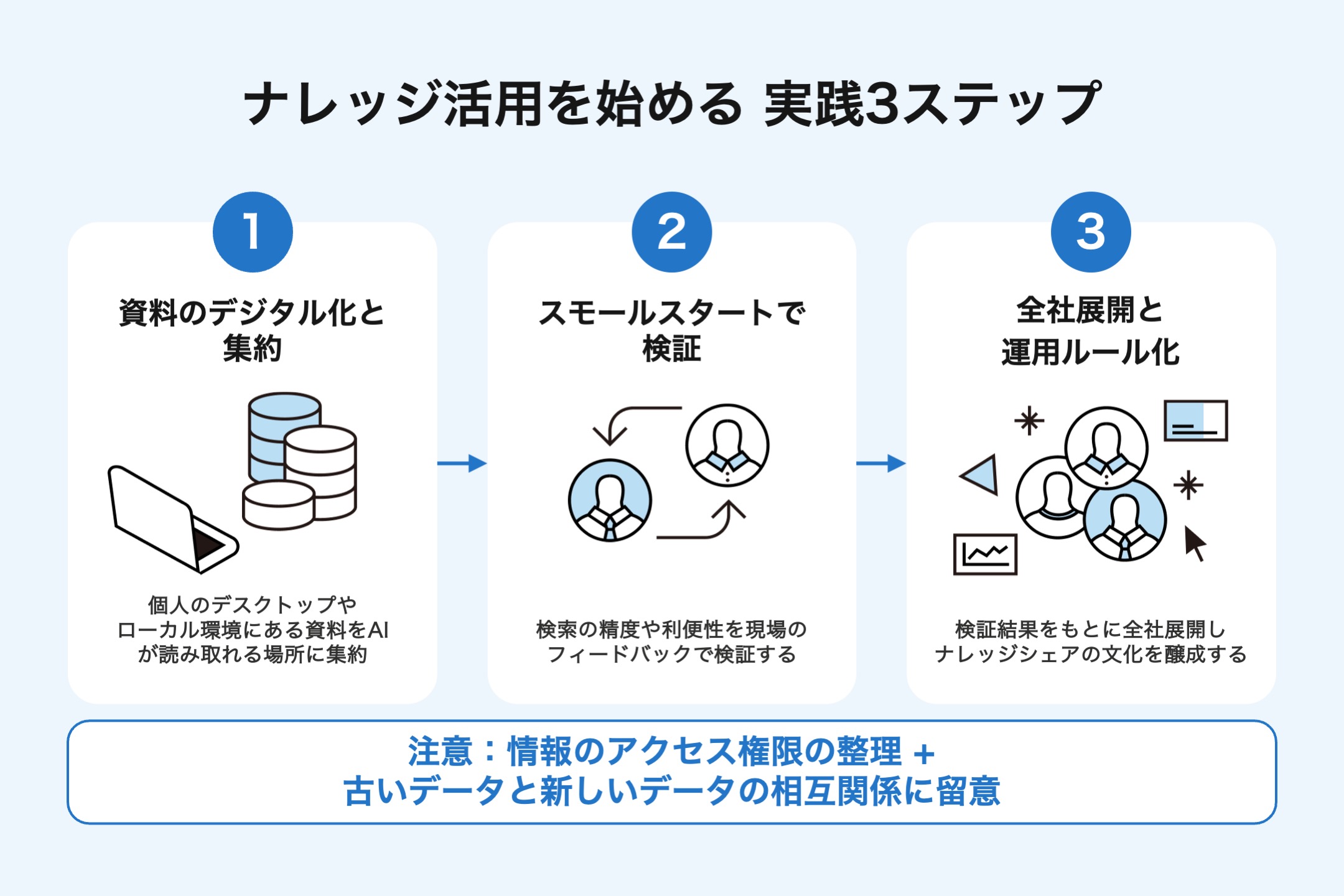
組織の知を武器に変えるには、以下の手順で環境を整えるのがスムーズです。
- ステップ1:資料のデジタル化と集約 個人のデスクトップやローカル環境にある資料を、クラウドストレージや社内クラウドなど、AIが読み取れる場所に集約します。
- ステップ2:スモールスタートでの検証 まずは企画部や営業部など、資料作成頻度が高い部署に限定して試験導入し、検索の精度や利便性を検証します。
- ステップ3:全社展開と運用のルール化 検証結果をもとに、資料の命名規則や格納ルールを最小限に定め、全社的なナレッジシェアの文化を醸成します。
まとめ
ビジネスにおける成果は、「どれだけゼロから作ったか」ではなく、「どれだけ組織の知を活かせたか」で決まります。自分の記憶力やフォルダ整理に頼る段階は、もう終わりにしましょう。
埋もれていた過去の資産を、次の提案を強化するための材料として再活用する。「satto workspace」は、こうした新しいナレッジ活用の形を支援します。過去の知恵を、明日の武器に変える準備を始めてみませんか。